在电脑游戏中,形态各异的建筑,细节丰富的车辆,一切都很真实。他们的本质其实是一个个不同位置的点,这些顶点在空间中相互连成线,形成无数个三角面,再经过贴图、光照、着色等复杂的渲染过程,最终形成了我们看到的精美画面。从三角形的生成再到图像的输出,其中每一个步骤都需要显卡作为电脑里晶体管数量最多的核心组件,显卡有哪些结构?又是如何工作的?本篇文章我们以ROG Strix RTX 4080猛禽为例,带你从零开始认识显卡。
显卡外观


显卡的正面是用于散热的风扇,底部的黄色长条是传输数据和供电的PCI接口,侧面是装饰用的logo和供电接口,而尾部则是用来连接显示器的视频接口。
显卡通常会以侧插的形式安装在主板上,此时风扇会朝向机箱底部,视频接口则会出现在机箱尾部。从机箱的侧面观察,我们通常只能看到显卡的侧面和背板。

在显卡侧面靠右的位置是显卡的外接供电接口,与电源连接以后可以为显卡提供充足的供电。之前大部分显卡都在使用8in PCE供电接口,能提供225瓦左右的供电。高功耗显卡则需要使用多个8Pin才能满足要求。这张4080猛禽使用了最新的12V-2*6接口,体积十分小巧,单个接口即可提供高达600瓦的供电。华硕也设计出了无需外接供电的背插显卡,可以直接从主板取电,安装以后会更加的简洁美观,这样搭配特定的主板或者转接头才能使用。

这张显卡在满载时的功耗可以达到360瓦,为了有效的排出热量,巨大的散热模组占据了整张显卡90%的体积,而最下面这张小小的电路板其实才是显卡的本体,也是热量的来源。
散热

散热模组由风扇、鳍片、热管与均热板构成,这里边的核心是热管,热管的内壁是由粉末烧结成的多孔结构。在制造成型后,热管内部会填充少量的高纯水并被抽成真空,以降低水的沸点和凝固点。当热管的一侧接触到热源以后,这一侧的水就会蒸发为水蒸气,往压强更低的另一侧飘荡,在温度更低的区域释放热量,重新凝结成液态水。而凝结的液滴会在毛细作用下沿着多孔的内壁回流,达成气液循环,通过气体液体的转化实现热量的高效传导。

为了提高导热效果,大部分显卡会使用多根热管来传递热量。但热管直接接触核心不仅会有空隙,还会有热管无法接触到GPU芯片。所以现在高端显卡一般会使用大铜底包裹热管进行均热。一些高端显卡会使用导热能力更强的均热板取代大铜底。
均热板可以理解为面积非常大的板状热管,同样采用气液转换传递热量,导热能力是纯铜底的数倍。不过热管和均热板能提供的对流面积非常有限,因此还需要搭配大量的铝制散热鳍片,扩大散热面积,最后通过风扇加强空气对流,带走鳍片上的热量。
早期的显卡采用下压式风扇设计,从风扇面进风从侧面出风。现在显卡为了提高散热效果,会采用贯穿式风道设计,热量可以直接从背板的格栅处排出。这张4080的风扇还使用了特殊的设计,中间的风扇与左右两侧的风扇旋转方向不同,保证风扇之间的气流方向相同,从而更高效的排出热量并降低噪音。
显卡本体

这张小巧的电路板是显卡的本体。排除掉一些零散的电容和芯片,可以把这块电路板从外往里划分成四个部分:
- 接口
- 供电
- 显存
- GPU
GPU相当于显卡的大脑,负责几乎所有的运算任务。要注意GPU并不等于显卡。GPU通常指的是最中间的这块芯片,而显卡指的是包括芯片显存、供电接口、电路板以及散热模块的整体。GPU芯片主要由英特尔、AMD和nvidia三家厂商供应。而我们熟知的华硕等AIC厂商主要完成的是电路板与散热的设计和生产。
就像主板上所有的元器件都是为CPU服务一样,显卡电路板上的所有元器件也都是为GPU而服务的。
接口
视频接口让显卡可以直接把运算好的图像发送给显示器显示。这张4080猛禽搭载了2个HDMI2.1和3个DP1.4接口,不同版本的视频接口能承载的分辨率和刷新率不同。
PCI接口让显卡能够通过主板和CPU内存等其他元器件交互数据,它的数据传输能力和版本以及规格有关。比如这张4080显卡用的就是PCI 4.0*16接口,在主板同样支持PCE 4.0的情况下,单条4.0通道每秒可以传输2GB的数据,16条总共可以传输每秒32GB的数据。
供电模块

供电模块保证了显卡有充足的电力分配,它们分布在GPU和显存的外围,由PWM芯片、电容、电感和mos管组成。电源会从右上方的供电接口输入正12伏的供电,之后再由供电模块降压至1.1V与1点35V输,送给GPU与显存。
显存

CPU在计算时需要把数据临时存放在内存里,而高速运行的GPU同样需要把数据暂存在显存里。GPU周围黑色的小方块就是显存这块4080猛禽使用的是最新的GDDR6X显存频率1400MHz,每颗显存都是2GB的容量,32bit的位宽,8颗一共16GB 256bit。
显存的总带宽是由频率、位宽还有显存类型共同决定的。显存的频率代表一秒钟可以传输多少个周期,位宽代表显存一次可以传输的数据量。GDDR6X显存每个周期内可以传输16倍的数据。把它们相乘,再把bit换算成Byte以后,就得到了716.8GB/s的总带宽,代表显存每秒能传输的数据量。
GPU组成
一般来说,游戏的分辨率越高,贴图和模型越精致,对显存容量和带宽的要求就越高。但在显存够用的情况下,显卡的性能还是由显卡的核心GPU来决定。这张RTX4080显卡搭载的GPU芯片叫做AD103-301。它使用的是nvidia最新的艾达洛夫伦斯架构,面积只有379平方毫米,不过一个矿泉水瓶盖大小,但内部却集成了整整459亿颗晶体管。
之所以能有这么高的晶体管密度,靠的是台积电先进的5纳米光刻工艺。台积电会根据英伟达的设计方案,在1块12英寸的硅晶圆上,通过复杂的生产工艺刻制出复杂的电路图案。数量庞大的晶体管在GPU的内部组成了复杂的电路结构,就像一座微缩的城市。其中大部分的电路都可以用于图形运算。
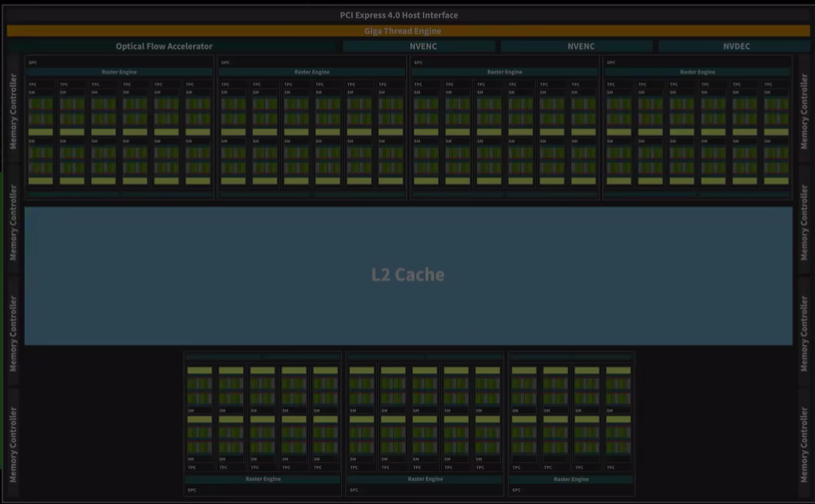
GPU结构主要由SM流式多处理器、L2缓存、NVENC视频编码器、NVDEC视频解码器、显存控制器和PCE控制器构成。
SM流式多处理器占据了GPU的大部分面积,它负责了几乎所有的图形运算。这颗AD103-301核心里一共有76组SM单元,每组SM单元里包含128个流处理器,总共9728个流处理器。英伟达把这些流处理器叫做CUDA核心显卡的流处理器数量越多、频率越高性能就会越强。

如果把每组SM类比成一个CPU核心,那么这颗GPU就相当于一颗76和9728线程的处理器。不过CPU核心就像经验丰富的数学家,能处理更加复杂的任务。而GPU核心更像是只会四则运算的小学生,适合做简单的并行计算。在AI模型的训练和推理,3D游戏里的图形渲染都是需要这样大量简单计算的场景。显卡核心的数量优势就比CPU核心的质量优势更加有效率。
游戏画面渲染原理
要理解为什么显卡更适合这样的运算,我们就需要了解一下游戏画面到底是如何渲染的。在一个空间中,两个顶点可以连成一条线,三个顶点能组成一个三角面,千千万万个三角面就构成了一个精美的模型。真实的物体还需要更多的色彩和细节,所以还要给模型加上贴图。

在三维空间中,每个模型都有自己的位置,模型上所有的顶点都有对应的坐标,而无数个带坐标的模型共同构成了这个世界。想要观察这个世界,我们还需要一个虚拟摄像头,只有位于摄像机视野范围内的模型才会被渲染出来。同时这些模型相对于摄像机的位置也会被重新计算,得到新的坐标值。摄像机所捕获到的这些画面实际上是一个二维平面,三维空间中的模型需要通过投影的方式映射到这个平面上。最后我们需要将这个二维画面显示在由像素点构成的屏幕上。为了获得最终的渲染效果,我们还是要对每个像素点的纹理、光照和颜色等属性进行单独计算。经过这一系列复杂的运算,才能最终生成一帧在屏幕上显示的图像。

计算的过程中三角面的顶点做。一般用32位的0和1来表示,第一位为符号位,中间八位为指数位,后23位为尾数位。我们把这个叫做FP32单精度浮点数。
流畅的画面需要每秒30帧甚至60帧以上的图像,而每一帧都需要大量精确的数学计算。每秒钟能算的次数就是单精度浮点数算力,可以用来衡量图形渲染的性能。而TX4080的GPU核心,可以让9728个CUDA核心同时进行单精度浮点计算。在2800MHz的频率下,可以提供大约54 TFlops的单精度浮点算力,意味着每秒钟能计算54万亿次。而像i9这样的高端CPU,FP 32的算力也只有2.5 TFops。对比之下你就会发现GPU比CPU更加适合图形计算。
单精度浮点主要影响的是游戏图像的渲染性能。在这颗4080的GPU核心中,所有的CUDA都能计算单精度浮点数。除了能计算单精度浮点数FP32之外,同时向下兼容精度更低的半精度浮点数FP16,但只有一半的CUDA能支持int 32的整数计算。英伟达会把不同GPU支持的具体算力标注在官网上供大家查询。
GPU架构
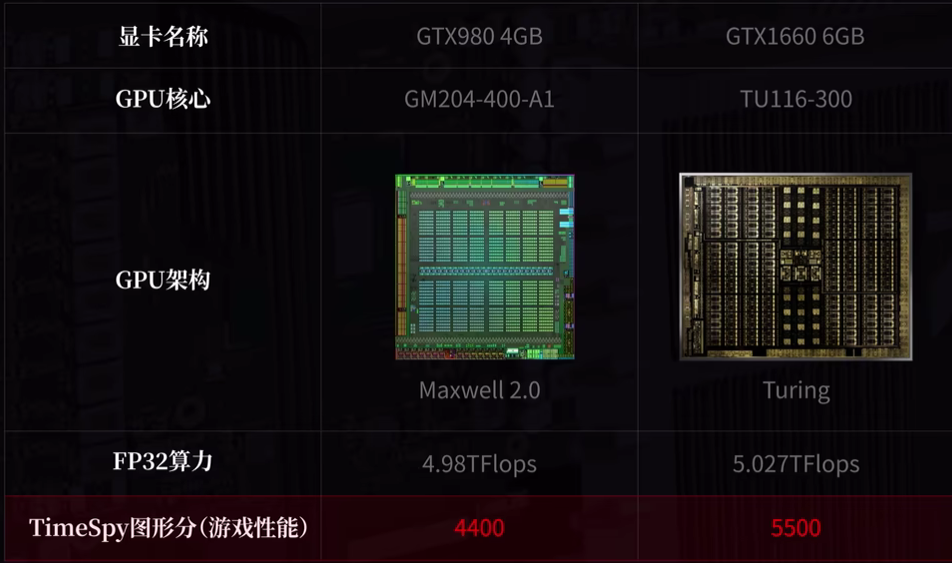
需要说明的是GPU的算力和架构有关,架构是GPU的设计方案,设计方案越先进,相同算力下的图形渲染效率就越高。比如GTX1660的GPU架构比GTX980更先进。虽然他们的FP32算力差不多,但1660的游戏性能却明显更强。所以nvidia在官网标注算力的时候,还会同时标注GPU的架构。

张量核心
单精度浮点算力和架构共同决定了GPU的游戏性能。但现在的GPU除了玩游戏和做渲染建模之外,还承担了许多AI相关的任务。在CUDA核心的右边是第四代tensor core张量核心,它非常适合做AI相关的深度学习计算。所有的tensor core一共可以提供780AI tops算力。比如说现在的AI绘图软件就可以调用tensor core,生成图片的速度远远比酷酷的要快很多。游戏里的DLSS功能同样可以调用tensor core,用更低的分辨率渲染,再通过AI上采用到更高的分辨率,从而提升游戏的流畅度。
光追核心
逼真的游戏画面还离不开真实的光照效果,而光线的反射和折射需要庞大的算力。这张4080的核心中,每组SM里都有一颗第三代RT Core光线追踪核心,专门用来加速光照和反射的计算,一共可以提供113RTT flops光追算力。光线追踪可以明显提升画质,但也非常的吃性能。如果用的是低端显卡,开了光追以后就可能很卡顿,只有性能更强的高端显卡才适合开启光线追踪。
其他单元
在SM单元之外还有很多其他的单元。视频解码器让显卡能把0101的数据转换成连续播放的视频画面。解码器性能过弱,就可能在播放视频时出现卡顿、掉帧。视频编码器则可以让你把拍摄到的视频数据以新的编码方式压缩成真实的格式和大小。而编码器性能弱弱,则会在剪辑视频导出时浪费过多的时间。显存控制器让GPU和显存得以顺利交互,数据PCIE控制器则让显卡能和主板上的CPU内存、硬盘等其他元器件交互数据。
除开上述内容,显卡的电路板上还有很多其他的附属芯片和接口,他们共同协作让显卡得以顺利运行。
挑选适合自己的显卡
挑选一张显卡的顺序大概可以按照性能需求、GPU型号、AIC品牌、实际产品这四个步骤来考虑。
性能需求可以借助TimeSpy天梯图做参考,在各个网站里你都可以搜到,它将显卡的跑分从高到低依次排列。虽然跑分和实际的游戏性能会略有差异,但是一个非常值得参考的数据,在天梯图里随便盲选一张显卡,然后搜索它的评测类节目,大概就可以知晓这张显卡在不同游戏中可以看到什么样的画质,达到什么样的流畅度,也可以看到它在专业软件中和其他显卡之间的性能差异。最后去查询这张显卡的价格。京东与官方旗舰店还有天猫旗舰店是存在一定的溢价的,建议使用淘宝第三方店作为价格参考,这样你就知道了多少钱可以买到一张跑分多少,性能如何的显卡。如果觉得超出预算,就在天梯图里往下找,如果觉得性能不太满足要求,那么就往上找,多看几张显卡的性能评测与价格,几个来回下来平衡一下预算和性能需求,该选择什么型号的GPU就非常清晰了。
确定好GPU型号以后,网上一搜就会发现,虽然都是4070,却有着各种各样不同型号不同品牌的显卡,不免让小白们犯难。这里我们其实可以剥离成两部分来看,一部分是品牌,另一部分是品牌内部的子型号。由于AIC品牌只完成电路板和散热模块的设计与生产,所以在确定了GPU型号是4070以后,各个品牌之间的性能差距不会非常的大不同。品牌之间的差异主要集中在外观、散热、噪音、做工用料、售后以及特色功能上。而这些也往往和各家品牌内部的子型号挂钩。

上图是目前市面上通过了官方认证的主流AIC厂商。通常来讲我们会更建议小白选择例如华硕这样的一线大厂,他们的全自动化制程技术不仅在品控上更有保障,大品牌在售后服务上也会更加完善。如果你看中的品牌不在这个表里,那建议谨慎考虑。
在品牌内部也划分有子型号,虽然GPU型号相同,性能差距也不大,但这些子型号往往决定了显卡的用料水平。高端产品线往往具有更强大的供电、更好的散热、更低的噪音、更好的超频空间以及更拉风、更炫酷的外观,但通常也会更贵。低端产品线可能在散热、噪音、用料以及外观上相较于旗舰产品会欠缺一些,但它的价格也相对便宜,适合那些追求性价比的用户。到底是选择更贵的旗舰,还是选择性价比高的主流产品,还是要根据自己的钱包喜好的外观、对噪音和温度的接受程度以及是否要超频来决定。
发布者:硬件先生,转转请注明出处:https://hardwaresman.com/graphics-card-composition-and-buying-advice/